마이크로 소프트 윈도우는 다양한 국가에 언어를 지원하기 위해서 유니코드 문자를 지원하는데
유니코드 변환 방식으로 UTF-16를 사용합니다. (UTF는 Unicode Transformation Format임)
다양한 유니코드 인코딩 방법
- UTF-8
- 하나의 문자를 나타내기 위해서 1, 2, 3, 4바이트로 인코딩을 수행(가변길이)
- 0x0080 이하라면 1바이트로 표현 (이진으로 1000 0000 = 0x0080)
- 0x0080 ~ 0x07FF라면 2바이트로 표현 (이진으로 0111 1111 1111 = 0x007FF)
- 0x0800이상은 3바이트로 표현
- 추가적으로 4바이트로 표현하는 방법을 제공합니다.

- UTF-16
- 각 문자를 2BYTE로 표현합니다.
- 가변길이가 아니기 때문에 보다 쉽게 다른 언어로 변경할 수 있습니다.
- 거의 대부분의 문자를 표현 가능하지만 일부를 위해서 4바이트 인코딩 방식도 존재
- UTF-32
- 각 문자를 4BYTE로 표현합니다.
- 가변 길이 인코딩 방식을 사용하고 싶지 않은 경우 유용합니다.
- 일반적으로는 메모리 사용이 비효율적이어서 파일 저장 및 데이터 전송으로 사용하지 않습니다.
일반적으로 C언어는 char 자료형으로 ANSI 문자를 표현합니다.
char c = 'A';
char szBuffers[260] = "Window c programing"
윈도우에서는 UTF-16의 문자열을 표현하기 위해서 wchar_t 자료형을 사용합니다.
wchar_t c = L'A';
wchar_t szbuffers[260] = L"Window c++ programing";문자열 앞에 대문자 L을 붙여 컴파일러에게 문자열을 유니코드라고 명시합니다.
윈도우에서는 C언어의 자료형으로 부터 구분지으려고 WInNT.h헤더에 자료형을 정의합니다.
typedef char CHAR;
typedef wchar_t WCHAR;ANSI문자와 유니코드를 사용하는 단일 코드를 지원하기 위해서 TEXT 매크로를 지원합니다.
"TEXT매크로"는 UNICODE가 디파인 되어 있다면 유니코드, 안되어 있다면 ANSI로 표현됩니다.
#ifdef UNICODE
#define __TEXT(quote) L##quote
#else
#define __TEXT(quote) quote
#endif
#define TEXT(quote) __TEXT(quote)윈도우에서 문자열을 사용할 때는 TEXT를 사용하는 것을 권장합니다.
#ifdef _UNICODE
#define _tcslen wcslen
#else
#define _tcslen strlen
#endifC 런타임 라이브러리는 ANSI나 유니코드 함수가 개별적으로 구현되어 있습니다.
#ifdef UNICODE
#define CreateWindowEx CreateWindowExW
#else
#define CreateWindowEx CreateWindowExA
#endif
윈도우 라이브러리나 C런타임 라이브러리의 함수에서는 유니코드 함수와 ANSI함수를 셋트로 제공합니다.
일반적으로 윈도우 라이브러리에서는 유니코드 기반으로 구현을 한 후 ANSI기반 함수(유니코드로 문자열 변환 후)에서
유니코드 기반 함수를 호출하는 형식으로 구현되어 있습니다.
ANSI기반 함수를 호출 시에는 (문자열 변환 비용) + (유니코드 기반 함수 비용) 이 발생하기 때문에
유니코드 기반 함수를 호출하는 것이 더 효율적입니다.
안전한 문자열 사용 방법
우리가 일반적으로 알고 있는 문자열 함수인 strcpy와 wcscpy 함수를 호출 해 보면
최근 컴파일러에서는 해당 함수들에 안전성에 문제 때문에 _CRT_SECURE_NO_WARNINGS이 디파인 되어
있지 않다면 사용하지 못하게 설정되어 있습니다.
어떻게 안전성에 문제가 있는지 아래 설명을 통해 전달드리겠습니다.
WCHAR szBuffers[8] = L"";
wcscpy(szBuffers, L"0123456789123456789");위의 코드를 보면 크기가 8인 문자열 버퍼에 크기가 20인 문자열을 복사하려고 합니다.
우리가 이 코드를 보게 된다면 명백히 잘못된 코드인 걸 알고 있지만 wcscpy함수는 에러를 발견하지 못합니다.

위 코드를 실행시켜 디버그를 통해서 확인해보면 위 사진과 같은 메모리의 상태가 되어집니다.
빨간색의 범위는 szBuffers로 할당한 메모리 사이즈이고 실제로는 파란색의 3번째 줄 중간까지 버퍼가 복사된 것을
확인할 수 있습니다. 실제로 사용자가 원하지도 않는 메모리가 오버 플로우 되어서 오염이 될 가능성이 있는데
해당 문자열 함수는 문제에 대해서 전혀 예방을 하지 못하기 때문에 사용하면 안 됩니다.
_tcscpy_s
그렇다면 어떤 문자열 함수를 사용해야 할까요? 우리는 _tcscpy_s를 사용할 수 있습니다.
window의 tchar.h 헤더에 선언되어 있습니다. 유니코드와 _MBCS의 디파인이 되어 있냐에 따라서 안전한
C 런타임 라이브러리를 호출해 줍니다.

MBCS란 multi byte character set을 의미하는데 예를 들어 UTF-8 같은 형식을 의미합니다.
하지만 MSDN의 문서를 보면 아래와 같이 쓰여있습니다.

번역해보면 "이 문서에서 MBCS는 멀티 바이트 문자에 대한 모든 비 유니 코드 지원을 설명하는 데 사용됩니다.
Visual C ++에서 MBCS는 항상 DBCS를 의미합니다. 2 바이트보다 넓은 문자 세트는 지원되지 않습니다."
DBCS란 double byte character set을 의미합니다.
이제 _tcscpy_s를 사용해서 해당 코드를 구현 해 실행해 봅시다.
_tcscpy_s의 기본 사용법은 ( destination , destination 문자 개수, source)
문자 개수를 전달할 때는 _countof를 사용해서 쉽게 전달이 가능합니다.
WCHAR szBuffers[8] = L"";
_tcscpy_s(szBuffers, _countof(szBuffers), L"0123456789123456789");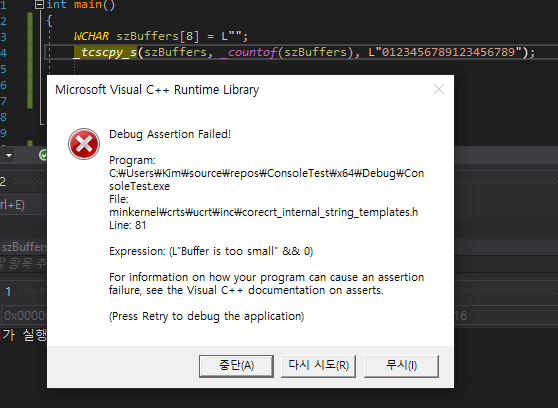
_tcscpy_s는 destination의 사이즈보다 더 큰 source를 복사하려고 하면 assertion을 통해서 알립니다.
메모리가 오염된 상태로 프로세스가 동작하는 것을 예방할 수 있습니다.
_tcsncpy_s 함수도 있는데 이 함수는 복사할 문자열의 개수도 전달합니다.
StringCchCopy
strsafe.h 헤더에서는 StringCchCopy라는 함수를 제공하는데 호출 방식은 _tcscpy_s와 동일합니다.
내부적으로는 유니코드일 때 StringCchCopyW, 아닐 때는 StringCchCopyA가 호출됩니다.
WCHAR szBuffers[8] = L"";
StringCchCopy(szBuffers, _countof(szBuffers), L"0123456789123456789");
이 함수의 경우 잘못된 버퍼 사이즈가 전달되면 위 사진에 보이는 것처럼
destination으로 전달된 버퍼만큼만 복사되고 나머지는 버려서 메모리 안전성을 제공합니다.
HRESULT 형식으로 응답 값을 제공하는데 성공 시에는 "S_OK"를 응답하고 버퍼가 부족시에는
STRSAFE_E_INSUFFICIENT_BUFFER라는 응답 값으로 문제를 알립니다.
Window에서 c++로 개발하는 개발자는 자신의 상황에 맞춰서 안전한 문자열 함수를 선택해서 구성할 수 있습니다.
'c++ > windows' 카테고리의 다른 글
| [window c++] 스레드 (0) | 2020.02.04 |
|---|---|
| [windows c++] 프로세스 (1) | 2020.01.31 |
| [Window c++] 커널 오브젝트 (0) | 2020.01.20 |
| [동기화객체] 조건 변수(Condition Variable) (0) | 2019.10.05 |
| [windows c++] 유저모드 스레드 동기화 방법별로 속도 측정 (2) | 2019.09.25 |